

Not all AI agents are created equal
A framework for categorizing and prioritizing your agent initiatives


👋 Hey there, I’m Lenny. Each week, I answer reader questions about building product, driving growth, and accelerating your career. For more: Lenny’s Podcast | Lennybot | How I AI | My favorite AI/PM courses, public speaking course, and interview prep copilot
P.S. Get a full free year of Lovable, Manus, Replit, Gamma, n8n, Canva, ElevenLabs, Amp, Factory, Devin, Bolt, Wispr Flow, Linear, PostHog, Framer, Railway, Granola, Warp, Perplexity, Magic Patterns, Mobbin, ChatPRD, and Stripe Atlas by becoming an Insider subscriber. Yes, this is for real.
Agents are so hot right now. Every other day, someone’s launching a new one or a new tool to manage them. I bet your team has a half-dozen agent ideas on your backlog right now. None of this means you actually need to build an agent today. But it does mean that you need to understand how agents fit into your broader strategy, and what the right investment looks like.
Hamza Farooq and Jaya Rajwani teach two of the most highly rated and well-respected courses on building AI agents (Agent Engineering Bootcamp and Agentic AI for PMs) and spent over 50 hours putting this guide together. By the time you finish reading this post, you’ll understand the three types of agents, how to decide which initiatives to prioritize, and how to avoid common pitfalls—with specific recommended tools and platforms and tons of real-life examples.
Let’s get into it.

Over the past year, we’ve had the same conversation at least 30 times. An AI leader pulls up their roadmap, usually 5 to 10 “agent” initiatives, and says, “Help us figure out which one to build first.”
The list usually includes a PM assistant, a RAG copilot, a customer support system, a code review agent, and a voice-enabled shopping assistant
If you’re reading this, you probably have a similar list. Your team is energized, investors are asking about it, competitors are announcing agent launches. You need to pick something and ship it.
That’s where most teams get stuck. The problem isn’t that they lack ideas; it’s that they try to prioritize fundamentally different kinds of systems as if they were the same thing. The usual approach is to reach for familiar planning tools. Teams open an impact-vs.-effort matrix and try to compare ideas side by side.
But with AI agents, that quickly falls apart. One “agent” might take six weeks to build. Another might take six months. One can be assembled by a product manager using n8n. Another requires a dedicated ML engineering team. One costs $500 per month to operate. Another could generate a six-figure annual LLM bill.
A customer support assistant and a voice-enabled shopping agent may both be called agents, but they demand different architectures, different teams, different infrastructure, and different timelines. Until you recognize those differences, any attempt to compare “effort” or “impact” is essentially guesswork.
Treating architecturally different products as if they’re in the same category makes effective prioritization nearly impossible. Prioritization breaks not because teams are bad at planning but because they’re comparing apples, oranges, and jet engines on the same spreadsheet.
The missing step is hierarchy
Before you can decide which agent to build first, you need to answer a more basic question: What type of agent is each idea actually proposing?
This will determine almost everything that matters for planning:
How complex it will be to build
What skills and infrastructure are required
How long it is likely to take
How expensive it will be to operate
How you should measure success
In other words, categorization isn’t just a technical exercise. It’s the foundation for smart prioritization.
This post gives you a decision framework you can start using today with your current roadmap.
We developed this framework from patterns we’ve seen while helping organizations turn agent ideas into real production systems. Working with enterprise teams across Fortune 500 companies such as Jack in the Box, Tripadvisor, and The Home Depot, we found that grouping ideas by their underlying architecture unlocks prioritization and significantly speeds up the development and launch process. These distinctions also mirror how the broader industry is beginning to classify AI agents, from automation workflows to reasoning systems and multi-agent networks (like the Levels of Autonomy for AI Agents paper and Types of AI agents by IBM). These are also the foundations of how massively popular tools like OpenClaw and Claude Code are actually architected.
If you’re staring at a backlog of agent ideas trying to figure out what to build first, here’s what you’ll have by the end of this post:
A 5-minute triage process to categorize every agent idea into one of three architectural types
A guide to picking the right tool/platform for your project (i.e. when to use n8n vs. LangGraph vs. ADK)
Success metrics and ROI frameworks tailored to each architectural type
Warning signs that you’ve picked the wrong path (and how to fix it)
You’ll be able to look at your backlog and know which ideas can ship in six weeks for quick ROI, which need three months but will drive significant revenue growth, and which are a six-month bet that only makes sense with the right resourcing and expectation setting.
All by first recognizing that “agent” is an umbrella term for very different kinds of systems.
The three agent categories
Every “agent” idea falls into one of three architectural categories.
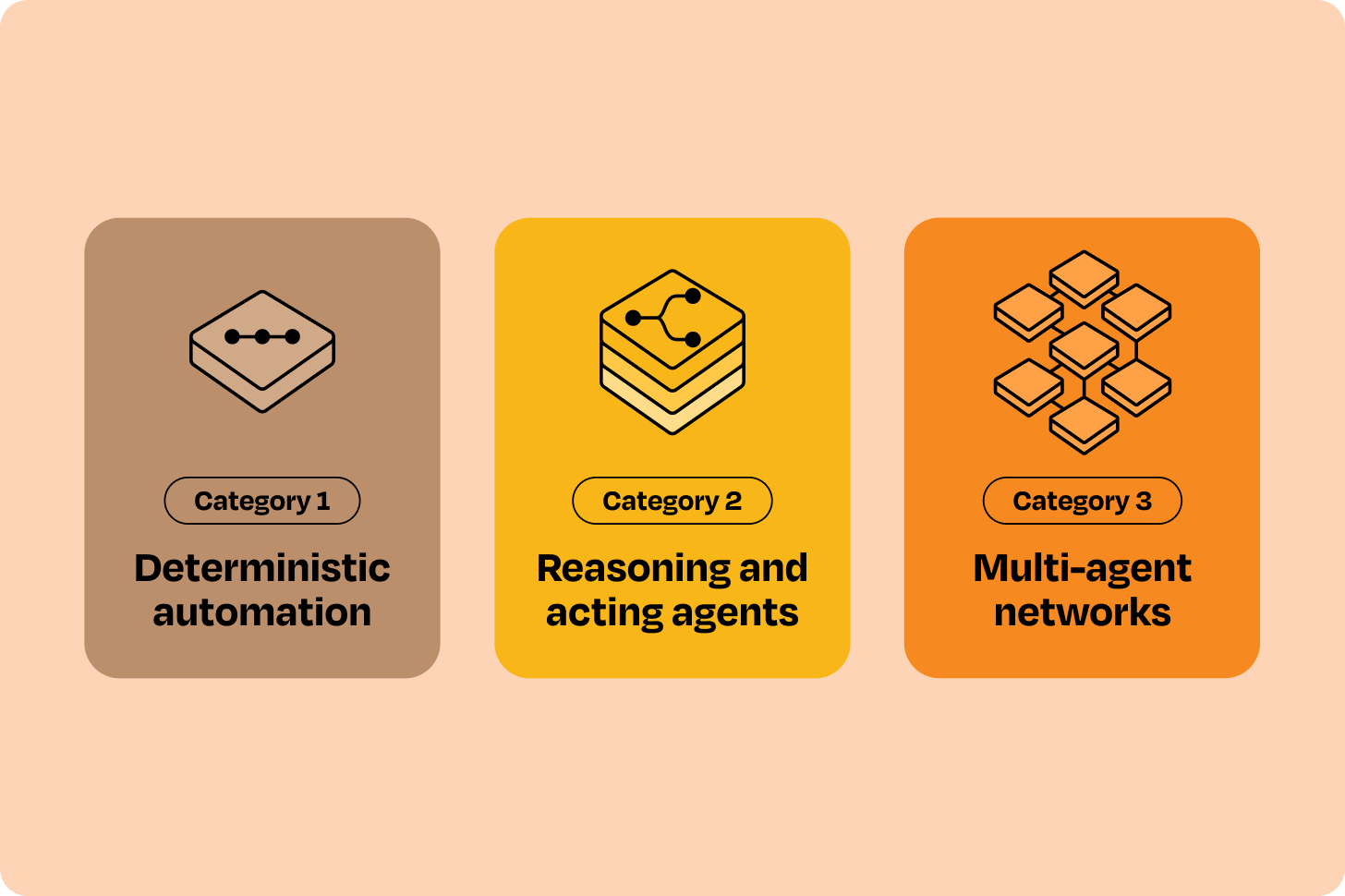
Category 1: Deterministic automation
You define the entire flow. AI handles content at specific steps. Think: n8n or Zapier workflows with LLM nodes. This is where the majority of agent opportunities belong and where most teams should start. These projects are fastest to launch and deliver measurable ROI quickly.
Category 2: Reasoning and acting agents
AI decides what to do next, using available tools. Think: Cursor, Lovable, or agents built with LangGraph, CrewAI, Google ADK, etc. These initiatives typically come after Category 1, when higher-value problems require flexibility and dynamic decision-making that workflows alone can’t handle.
Category 3: Multi-agent networks
Multiple specialized agents coordinate with each other. Think: enterprise systems built with ADK or AutoGen. These projects are typically reserved for later stages, when multiple teams must coordinate across domains, and should almost never be the starting point on a roadmap.
Some examples of “agents” that fit into each category to help you understand the differences:
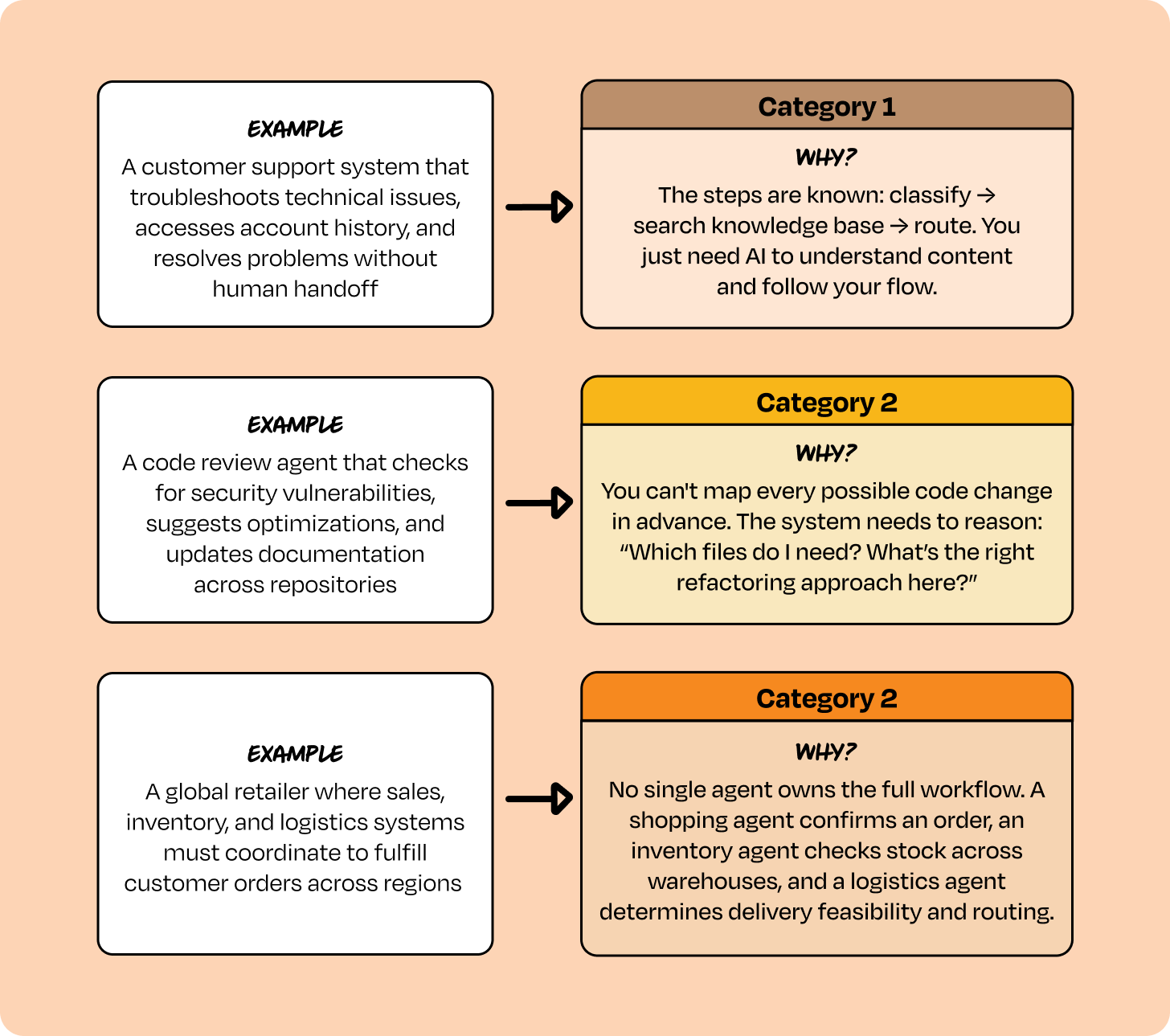
Organizations often try to build Category 1 problems with Category 2 frameworks—overengineering solutions that add unnecessary complexity and cost. Less frequently but with worse outcomes, they try to solve Category 2 problems with Category 1 tools, and it breaks in production because the tool is not robust enough.
Let’s take a deeper dive into each category, starting with the workhorse, Category 1.
Category 1: Deterministic automation
What this is
These are workflows where you define every step, every branch, every decision point. An LLM handles natural language understanding and generation at specific nodes, but you control the flow. Think of them as intelligent flowcharts where you design the path and AI handles the content.
Tools most commonly used for deterministic automation are n8n, Zapier, Make.com, OpenAI AgentKit, Lindy, and Gumloop. These tools are built around explicit triggers and predefined branching logic. You define the workflow, while LLMs are used only for classification, extraction, or drafting within those boundaries.
How to prioritize Category 1 products
If your backlog includes a mix of agent ideas, Category 1 projects are almost always the smartest place to begin. These initiatives tend to be the simplest to plan and the lowest-risk to execute.
They’re best suited to situations where the process is already well-defined and the goal is to automate repetitive, high-volume work. If you need quick, measurable ROI, have limited AI engineering capacity, or are under pressure to deliver results in weeks rather than months, Category 1 projects are almost always the right starting point.
Most initiatives in this category share a similar profile across certain criteria:
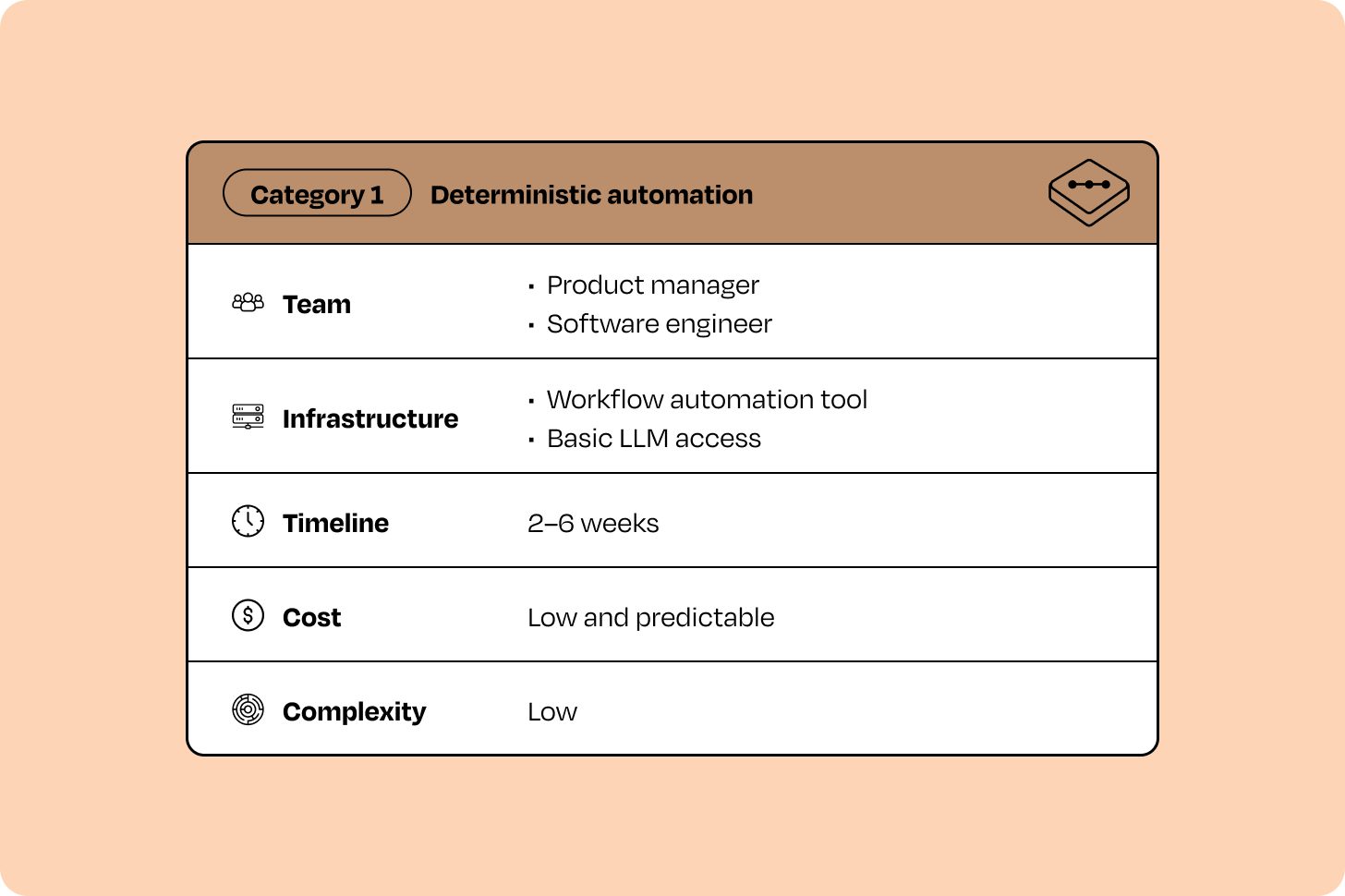
That combination of fast timelines, modest resources, and clear business impact is what makes Category 1 initiatives such powerful early wins. They generate near-term value while building organizational confidence for more advanced efforts later.
What types of products fall in this category
If you can map the entire process as a flowchart with clear decision points, a product belongs in Category 1. Here are some more traits of a Category 1 product:
Execution paths are finite and predictable (fewer than 15 to 20 branches)
Task completion needs to happen in seconds to minutes
The value is in automating a known process, not discovering new approaches
In our experience with customers, this covers 60% to 70% of agent opportunities. Revisiting the typical list of opportunities I mentioned above, here is a great example of a Category 1 product: “We need an AI agent to handle incoming customer emails, read them, understand what they’re asking, pull relevant information from our docs, draft replies, and route to our team for approval.”
At first, this sounds like it needs sophisticated reasoning. But when you map out what actually needs to happen, it’s remarkably deterministic:
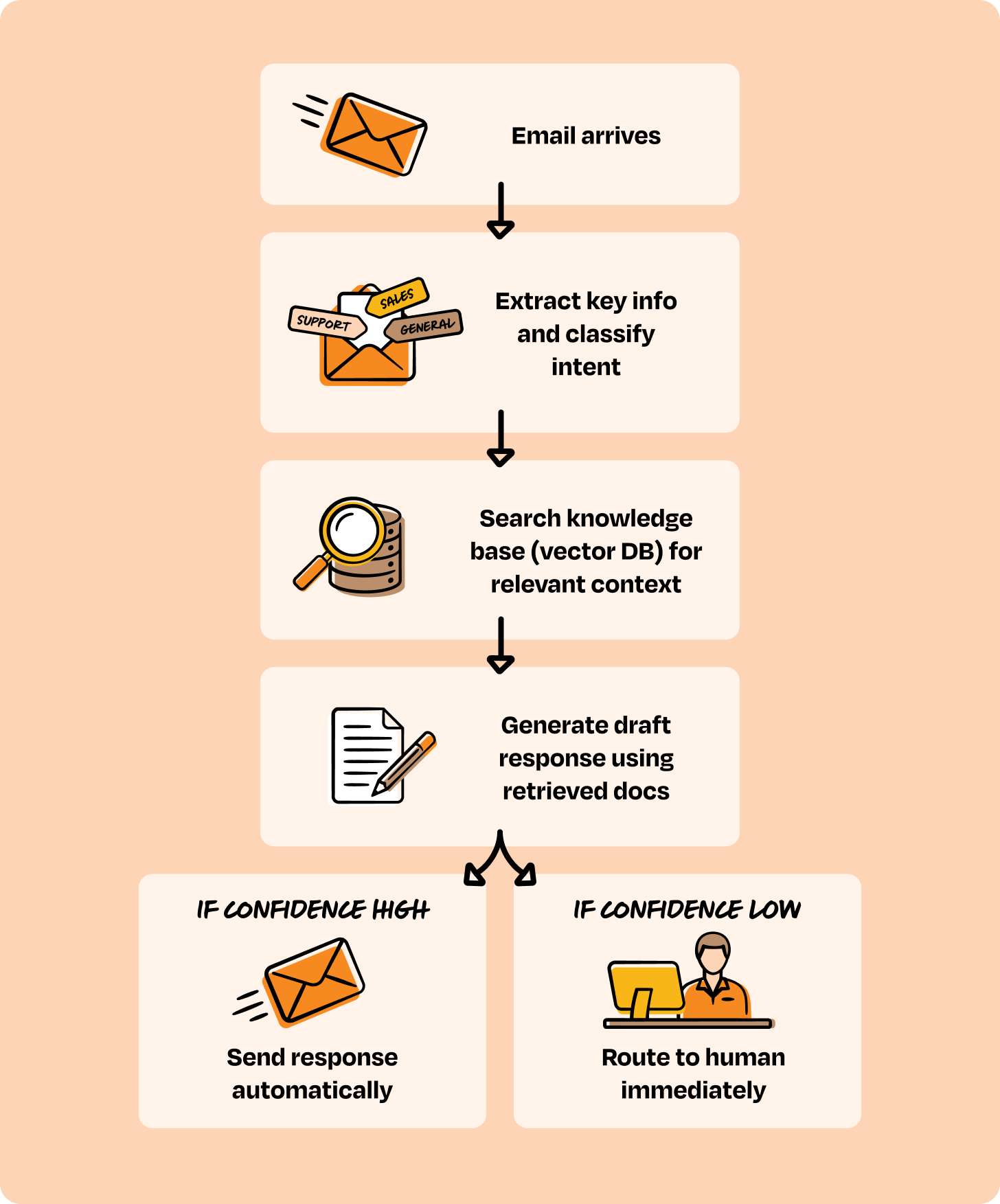
Every step is predictable. The “intelligence” is in understanding the email and generating a good response, not in figuring out what to do next. This is Category 1.
There are a ton of great examples of automation agents; here’s one built by me.
I love Airbnb, but I hate spending long hours finding the best ones, so I built an agent that will take my exact request for, e.g., “Modern apartment in Paris near train stations from 20th March to 26th March. Great for a couple” (more than 10,000 users have used it) and run a search. Here’s how you can build your own.
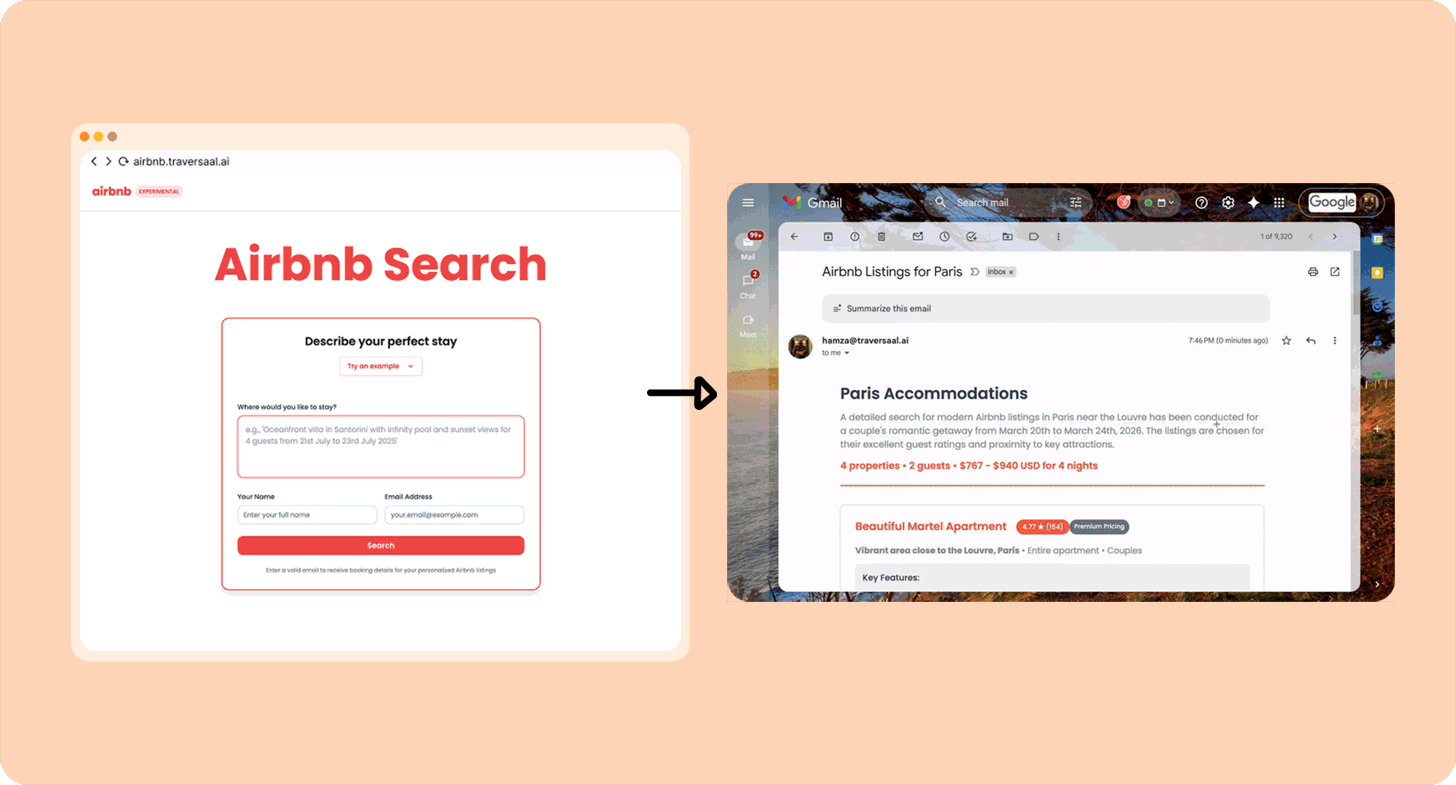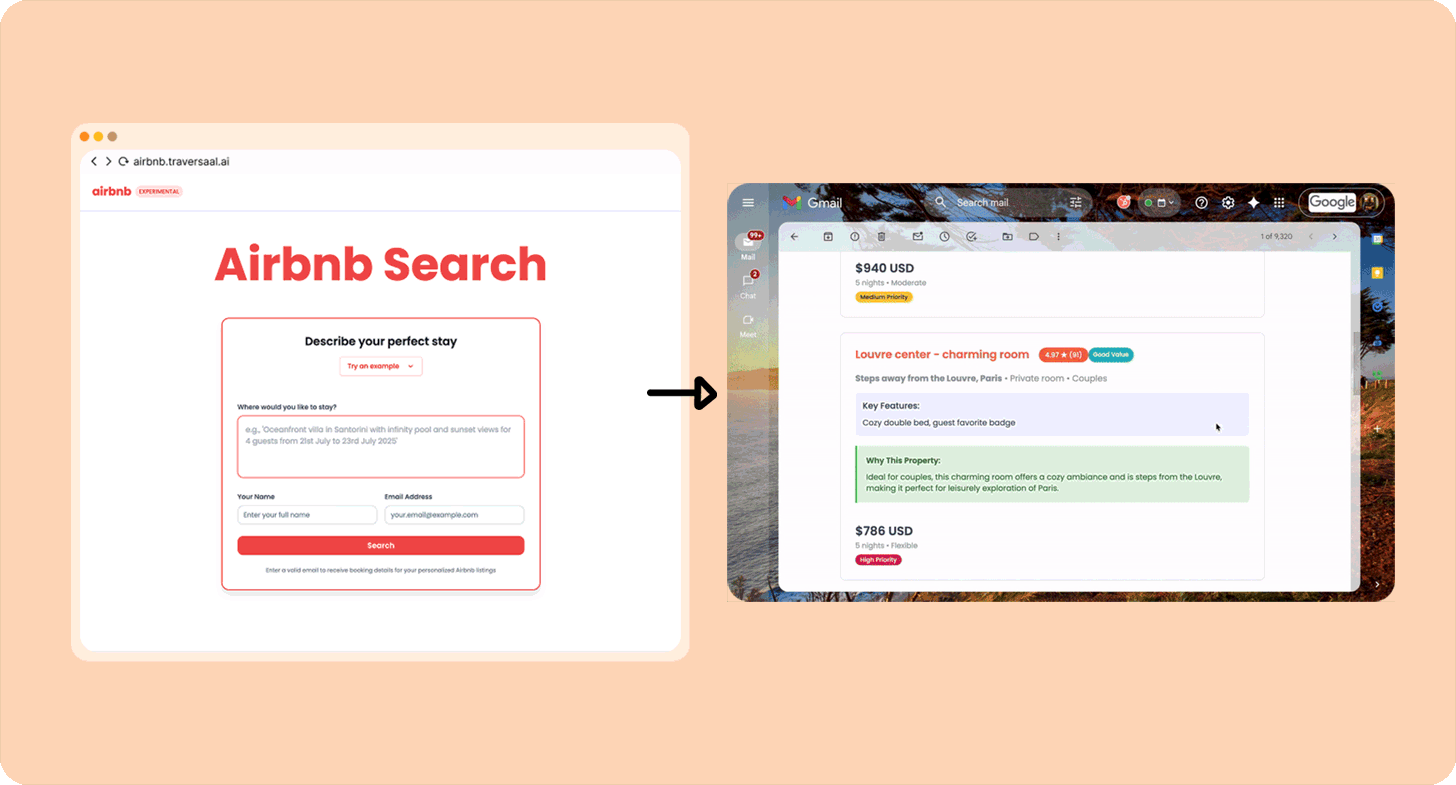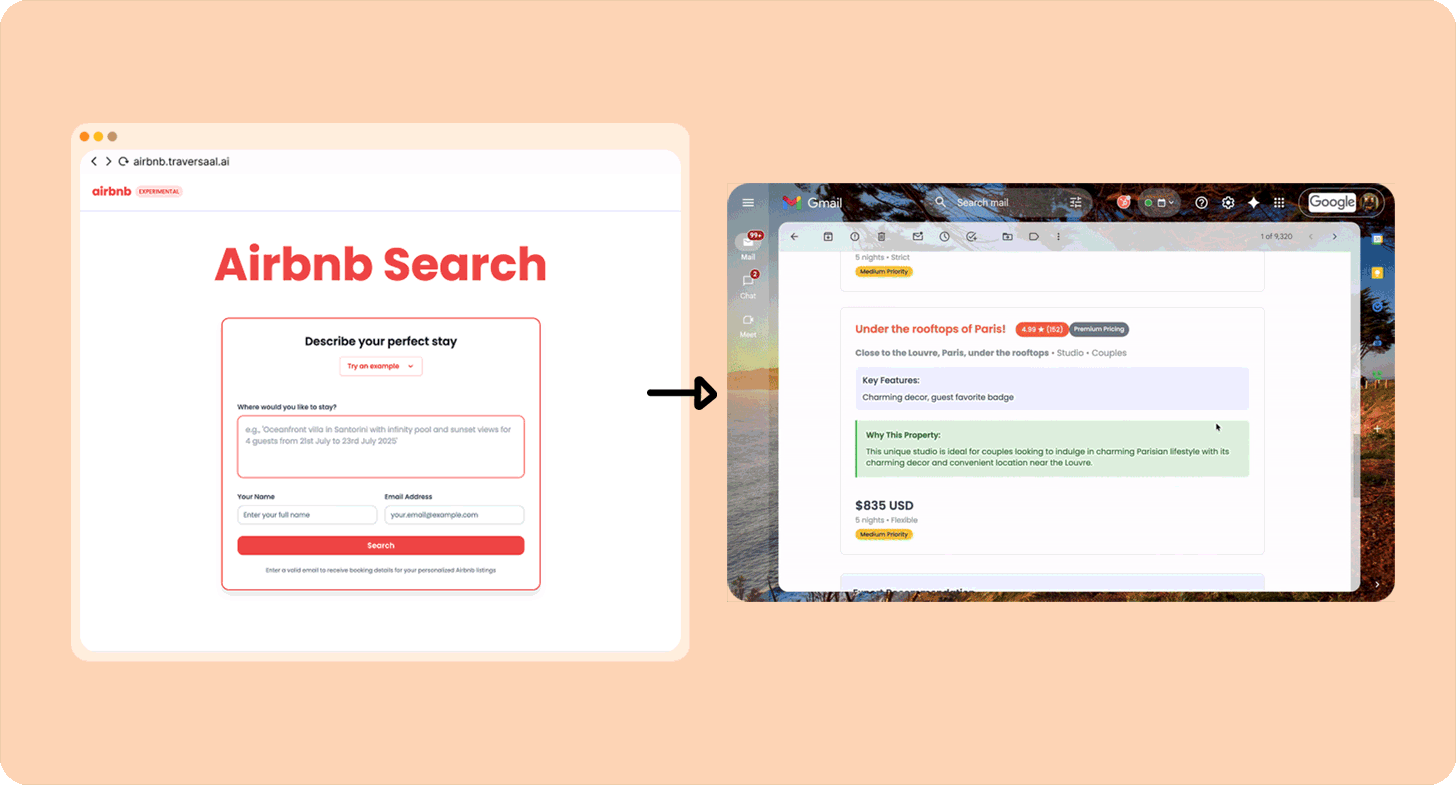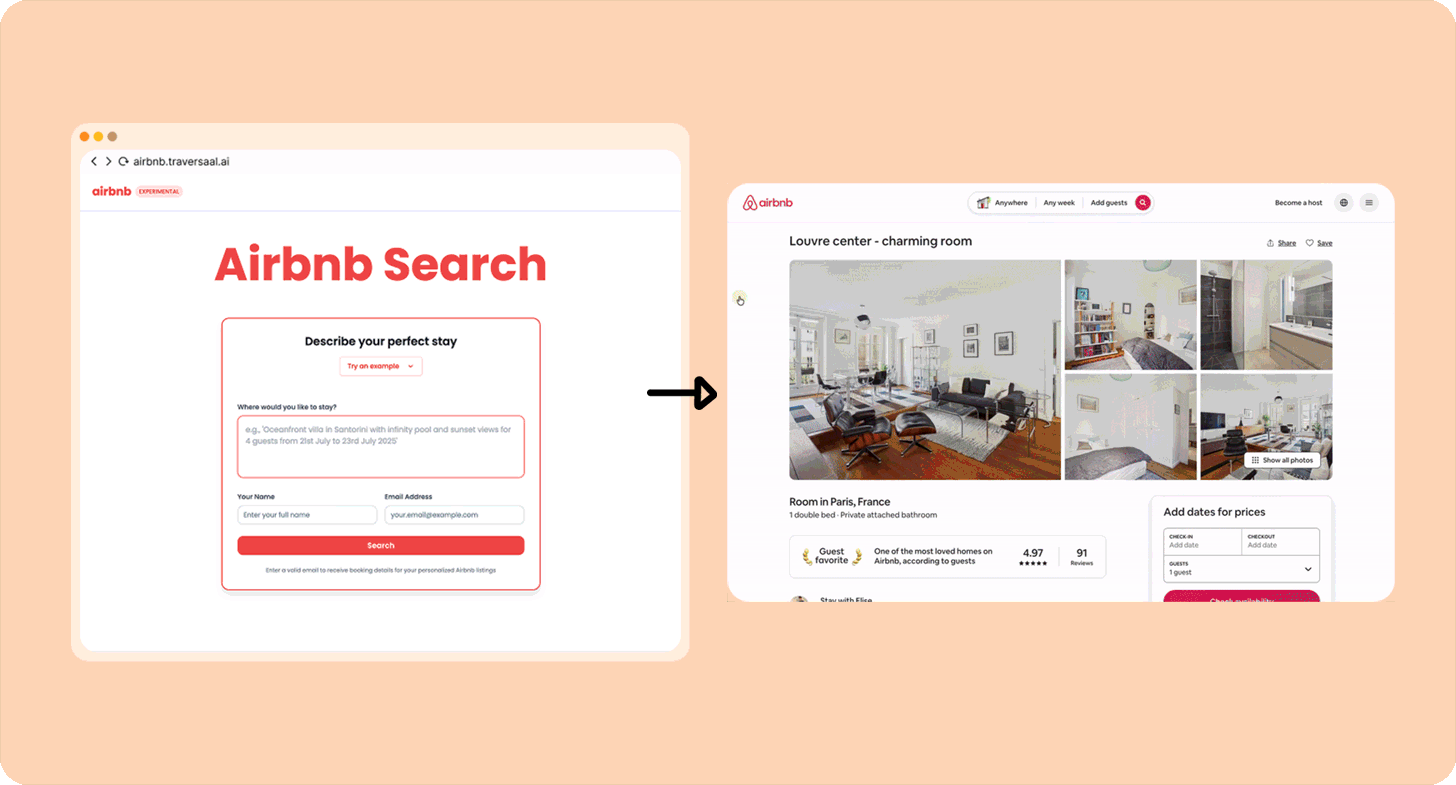
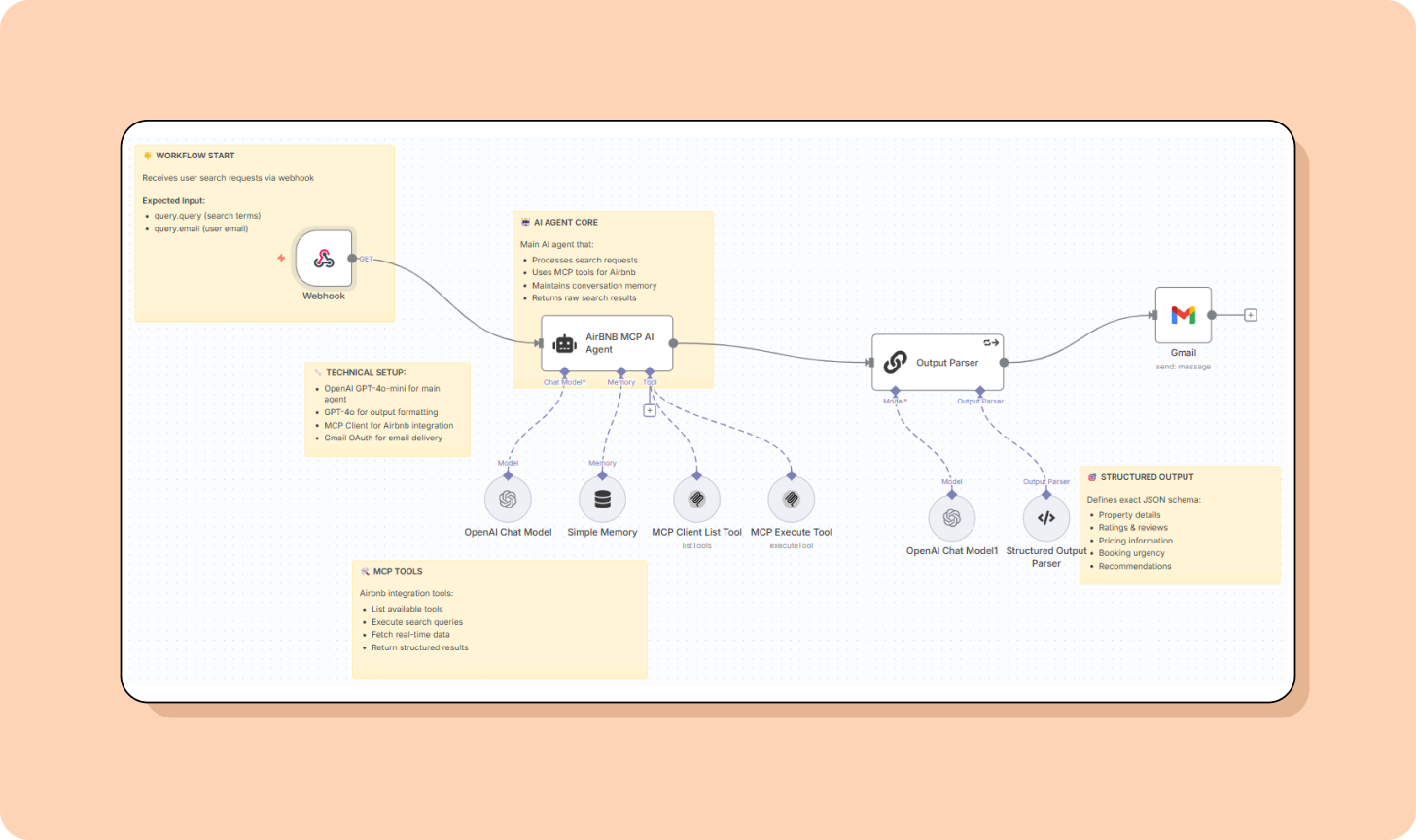
Other examples of Category 1 “agents”:
a travel planning agent
a voice-enabled book companion agent
a content automation agent (YouTube → LinkedIn)
a knowledge base of your organization with internet search (Perplexity clone)
an agent that generates deeply researched blogs, based on a given topic
a highly personalized calorie counter app that allows you to upload images of your meals to keep track of your daily caloric intake and recommends better dietary choices and exercises
How to evaluate Category 1 products
The metrics below are designed to answer a simple question: Did this agent automate the right process, or should this idea be reconsidered or re-scoped?
A deterministic agent built for the email automation process can be evaluated as follows:
Workflow completion rate: % of executions that finish successfully
Automation rate: % of requests handled without human intervention
Accuracy: correctness of intent classification, data extraction, and routing decisions
Latency: time from trigger to final output (P50/P95 if relevant)
Cost per workflow: total LLM and API cost per completed run
Error rate: % of runs failing due to tool, integration, or system errors
Human review rate: % of runs requiring manual approval or intervention
Here are workflow completion rate metrics from a real-life example of a Category 1 product, an email support agent built by a SaaS company we worked with:
Week 1: 52% completion rate (lots of edge cases discovered)
Week 4: 78% completion rate (refined classification logic)
Week 8: 87% completion rate (stable, production-ready)
Result: 3,000 support emails/month automated, 2.5 FTE hours/day freed, $18K/month savings
When these metrics stabilize and cost trends downward, the workflow is doing what it should. If completion remains low or manual intervention stays high, the problem may not be deterministic enough for this category.
How to know you’ve outgrown Category 1
You’ll know you need a different architecture when:
Your flowchart has 30+ nodes and you’re adding new branches every week
Customers phrase things in ways you can’t anticipate, and mapping all variations is impossible
The agent needs to decide which API or knowledge source to use based on context, not follow a predetermined path
Breaking down ambiguous requests requires exploration and adaptation, not predefined decomposition
The highest-value opportunities can no longer be expressed as predictable workflows
Most quick-win processes are already automated
If several of these signals are present at once, the problem is no longer a good fit for a deterministic workflow, and you should consider Category 2.
Category 2: Reasoning and acting agents (ReAct)
What this is
Instead of defining the flow, you define the available tools, and an LLM autonomously decides what to do next. The agent operates in a loop: observe → reason → act → observe result → repeat.
The key characteristic: you control the tools; the LLM controls the reasoning.
Tools most commonly used for building ReAct agents include LangGraph, CrewAI, AutoGen, and other agent orchestration libraries that support tool use, memory, and dynamic planning.
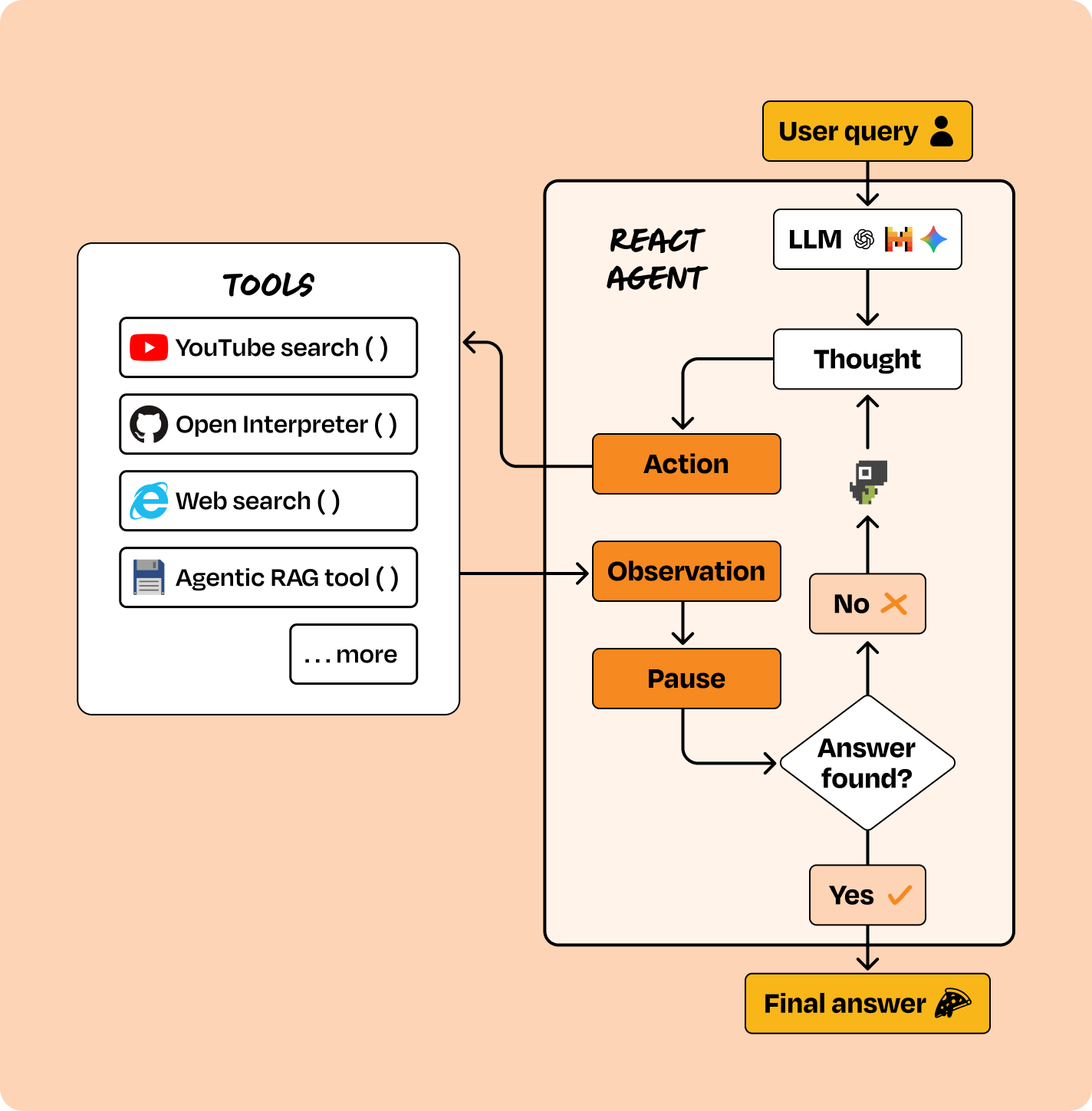
How to prioritize Category 2 products
Category 2 is for situations where user requests are ambiguous, workflows cannot be mapped in advance, and real value comes from flexible, contextual decision-making. If you need agents that can reason across multiple tools, handle conversational interactions, or adapt dynamically to new inputs, that’s a Category 2 product.
Category 2 products are more complex to plan and carry higher execution risk than Category 1. Most initiatives in this category share a similar profile:
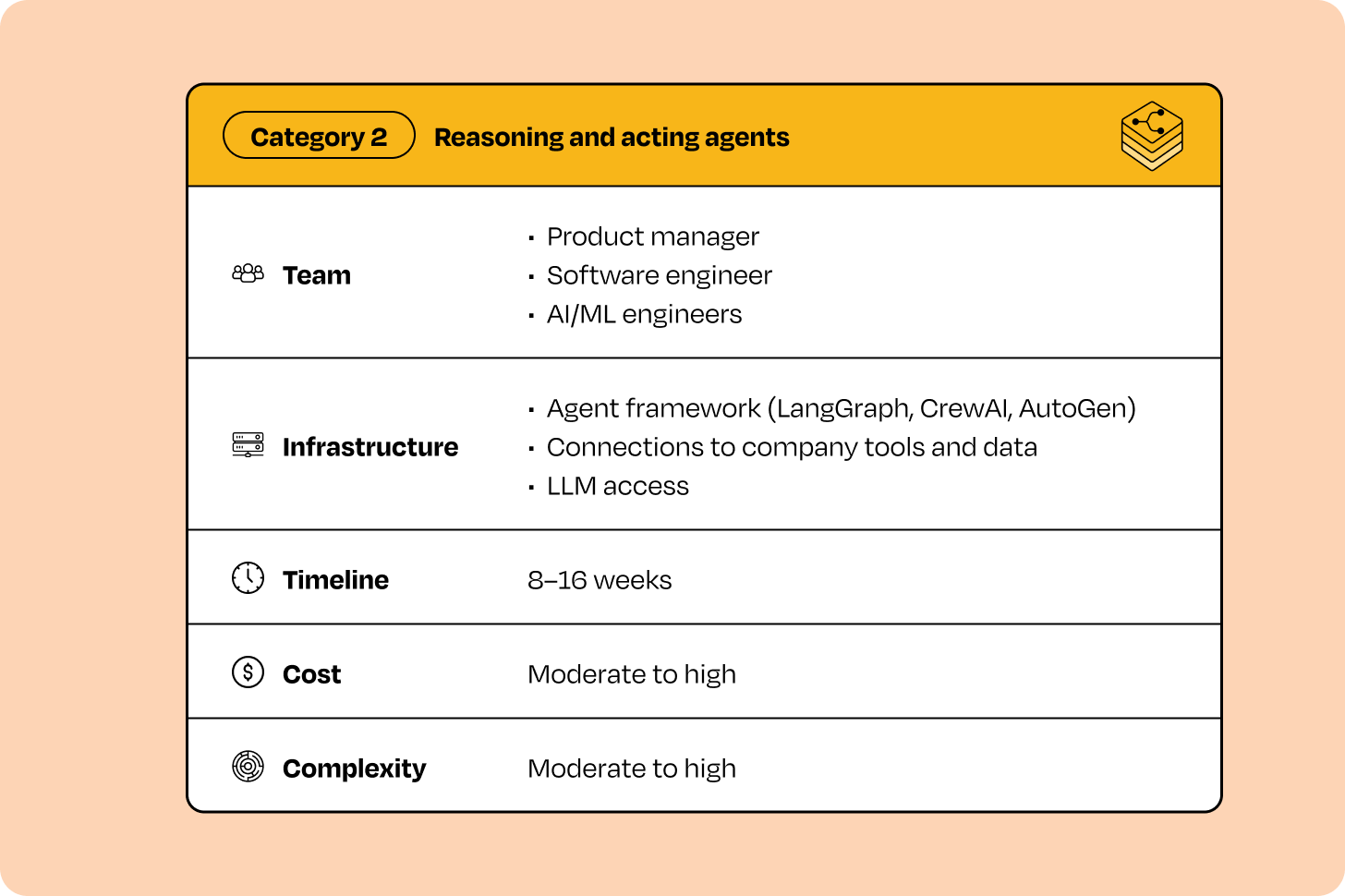
The combination of longer timelines, specialized expertise, and higher costs is what makes Category 2 initiatives powerful but more demanding than Category 1. If your backlog includes problems that truly require reasoning and dynamic behavior, prioritizing Category 2 projects becomes essential. They unlock use cases that deterministic automation cannot handle and enable more advanced, high-impact agent experiences.
What types of products fall in this category
A product belongs in Category 2 if the same user request can trigger different action sequences every time. That means that you don’t determine the path; the LLM does. That’s the key difference from Category 1. Here are some more traits of a Category 2 product:
The same high-level task requires different sequences of actions depending on input
You have 5-15+ distinct capabilities and the right one depends on context
User intent is ambiguous and needs clarification through interaction
Multiple input modalities (voice, image, text) need to be understood contextually
Breaking down complex requests into sub-tasks is part of the value
In our work with customers, this is the right choice for 25% to 30% of agent opportunities. For an example of this type of product, let’s return to the voice-enabled shopping assistant opportunity from the start of this post.
Customers should be able to search products by voice, upload images to find similar items, check order status, update preferences, and initiate returns, all through conversation.
At first, this sounds like Category 1. Just map out the intents and route accordingly, right? But in practice, real conversations don’t follow fixed paths. To see why, let’s walk through one interaction.
A customer uploads a photo of shoes and says:
“These are too small. I need a size up, and I want them delivered by Thursday.”
Here’s what happens under the hood:
Observe. The agent receives mixed input: an image + voice request.
Reason. It determines:
First, identify the product in the image
Then, find available size variants
Then, check delivery dates
Finally, confirm the order with the user
Act. The agent dynamically selects tools:
visual_search() → identify product
check_inventory() → find size-up availability
get_delivery_options() → verify Thursday delivery
place_order() → after confirmation
Observe result → reason again. Each tool response updates the agent’s state and influences the next step.
This sequence cannot be pre-defined.
If the item is out of stock, the agent may suggest alternatives.
If Thursday delivery isn’t available, it may propose pickup.
If the image can’t be recognized, it asks a clarifying question.
The same user request triggers different action sequences based on reasoned considerations.
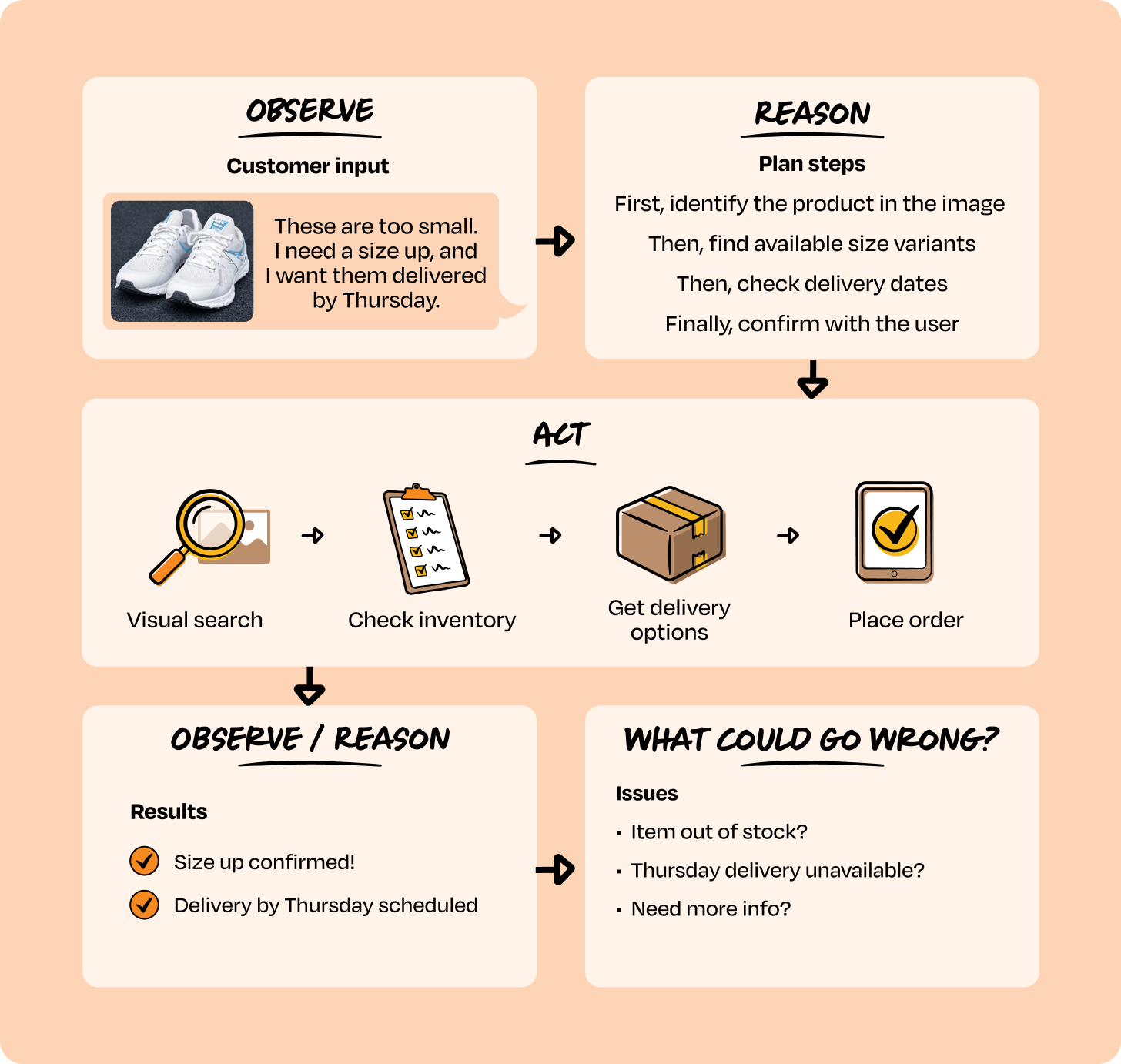
Other examples of Category 2 “agents”:
a conversational customer support agent
a code assistant that modifies repositories, e.g. Claude Code
an intelligent personal shopping assistant
an IT troubleshooting agent
a sales copilot that researches accounts and drafts outreach
a multimodal assistant combining voice, image, and text
How to evaluate Category 2 products
Reasoning agents should be evaluated on whether they help users achieve their goals across variable paths, while remaining efficient enough to justify their cost.
These metrics answer the question: Was dynamic reasoning necessary, or should the problem be simplified to a lower category?
Task completion rate: % of sessions where users achieve their intended goal
Reasoning accuracy: correctness of task decomposition, tool selection, and decision ordering
Conversation length: average turns to resolution
Multimodal accuracy: correctness of image, voice, or structured input interpretation (if applicable)
Tool call efficiency: average number of tool calls per successful session
Latency: time per turn and end-to-end session duration
Cost per session: total LLM and API cost per completed interaction
User satisfaction: post-interaction CSAT or equivalent signal
Business impact: lift in conversion, retention, or task success versus baseline
Here are some metrics from a real-life example, a voice + image shopping assistant for a home goods retailer we built:
Month 1: 71% task completion, longer conversations, higher tool usage, $0.12 cost per session
Month 4: 86% task completion, shorter conversations, fewer tool calls, $0.08 cost per session
Result: Image identification accuracy improved from 76% to 91%, conversion lift increased from +8% to +22%, and CSAT rose from 4.0 to 4.5.
When task completion improves while conversation length, tool usage, and cost per session decline, the agent’s reasoning loop is adding value. If performance stalls while costs remain high, the problem may be over-scoped or better served by the deterministic approach of Category 1 tools.
How to know you’ve outgrown Category 2
You’ll know you need a different architecture when:
Your single agent is trying to handle too many domains (customer service + inventory + logistics + finance) and performance is degrading
You need agents to delegate tasks to each other, not just call stateless APIs. Example: A shopping agent needs to ask an inventory agent, “Can you check all warehouses and suggest alternatives?”
Tasks take hours or days to complete (like the automated eval agent analyzing 10,000 conversations overnight)
You need hundreds of agent instances running in parallel, coordinating work among them
Different teams want to own their specialized agents, but they need to work together
If you’re hitting two to three or more of these, it’s time to consider Category 3 tools and approaches.
Category 3: Multi-agent network
What this is
Instead of one agent calling tools, you have multiple specialized agents that coordinate with each other. Each agent is owned by a different team, handles its own domain, and can request help from other agents.
 | A guest post by
|
 | A guest post by
|